Part 33 of 58
The Words Problem
By Madhav Kaushish · Ages 12+
Phlontjek's contract system was working. But the contract reader had been built for a specific format — fixed clauses with predictable structure. GlagalCloud's next challenge was far messier.
The Scribe's Archive
Hjentova was the chief archivist of Sonhlagot's royal library. She oversaw a collection of roughly two hundred thousand tablets — laws, histories, trade records, poetry, agricultural manuals, philosophical treatises — written in a dozen regional dialects of Sonhlagoti across three centuries.
Hjentova: I need a system that can read these tablets. Not classify them or predict values — read them. Understand the language well enough to answer questions, summarise passages, and translate between dialects.
Trviksha: My transformer can process sequences. But it processes pebble arrangements — numbers. Your tablets contain scratches — written language. I need to convert the scratches into numbers.
Hjentova: Each scratch is a character. You could assign each character a number.
Trviksha: I could. Sonhlagoti has forty-three characters. That is a manageable vocabulary. But individual characters carry almost no meaning. The character "k" tells the network nothing. The word "kvrothja" means a type of farmer. The meaning is in the word, not the character.
Whole Words
The obvious approach: assign each unique word a number. "Kvrothja" gets number 4,281. "Grain" gets number 712. "Deliver" gets number 1,043.
Trviksha counted the unique words across Hjentova's archive. The result: approximately eighty thousand distinct words, once she included all the regional variants, archaic forms, proper names, and technical terms from different domains.
Blortz: Eighty thousand words means eighty thousand entries in the vocabulary. Each word gets its own pebble arrangement — its own embedding. Eighty thousand embeddings to store and train.
Trviksha: That is large but not impossible. The worse problem is unknown words. If the network encounters a word it has never seen — a new place name, a misspelling, a rare dialect term — it has no embedding for it. The word is invisible.
Hjentova: My archive has many rare words. Historical names, obscure legal terms, words from dialects that are no longer spoken. A system that cannot handle unknown words is useless to me.
The Middle Path
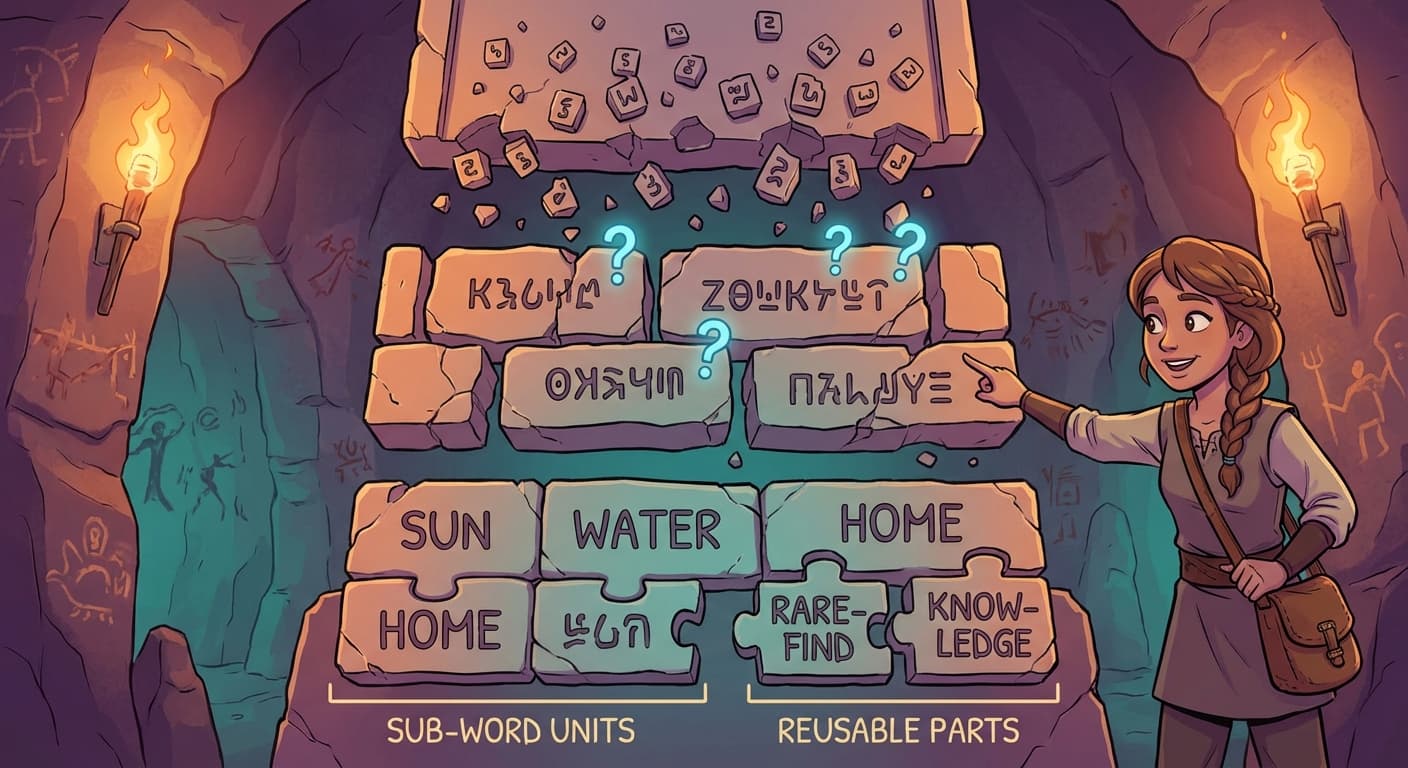
Trviksha experimented with an approach between characters and whole words. She broke words into pieces — sub-word units — that balanced vocabulary size with meaning.
The method was mechanical. She started with individual characters and iteratively merged the most frequently co-occurring pairs. The pair "th" appeared constantly, so it became a single unit. Then "the" merged. Then common suffixes like "ing" and "tion." After many rounds of merging, she had a vocabulary of roughly eight thousand sub-word units.
Common words like "the," "grain," and "deliver" survived as whole units — they appeared so frequently that they were merged early. Rare words were split into recognisable pieces: "kvrothja" might become "kvr" + "oth" + "ja." The pieces were not meaningful individually, but they were reusable — the sub-word "oth" appeared in many words, and its embedding could capture whatever those words had in common.
Trviksha: Eight thousand units instead of eighty thousand words. Every possible text can be represented — because in the worst case, the system falls back to individual characters, which are always in the vocabulary. And common words are efficient — represented by a single token rather than split into pieces.
Blortz: What about the embeddings? Each of the eight thousand tokens needs its own pebble arrangement?
Trviksha: Yes. Each token gets an embedding — a set of, say, sixty-four numbers — that the network learns during training. The embedding for "grain" will end up near the embedding for "wheat" and "barley," because those words appear in similar contexts. The network discovers the relationships between tokens from the patterns in the text.
Hjentova: How does it learn that "grain" and "wheat" are related?
Trviksha: From the company they keep. "Grain" and "wheat" appear in the same kinds of sentences, near the same kinds of words — "harvest," "field," "store," "price." The embedding is trained to predict context, and words with similar contexts end up with similar embeddings.
Hjentova: You learn meaning from usage. That is how children learn language.
Trviksha: It is a rough approximation of that, yes.