Part 46 of 58
The Tuning
By Madhav Kaushish · Ages 12+
Trviksha had three pieces: the pre-trained language model, the reward model trained on human preferences, and the reinforcement learning framework from the pterodactyl work. Now she combined them.
The Pipeline
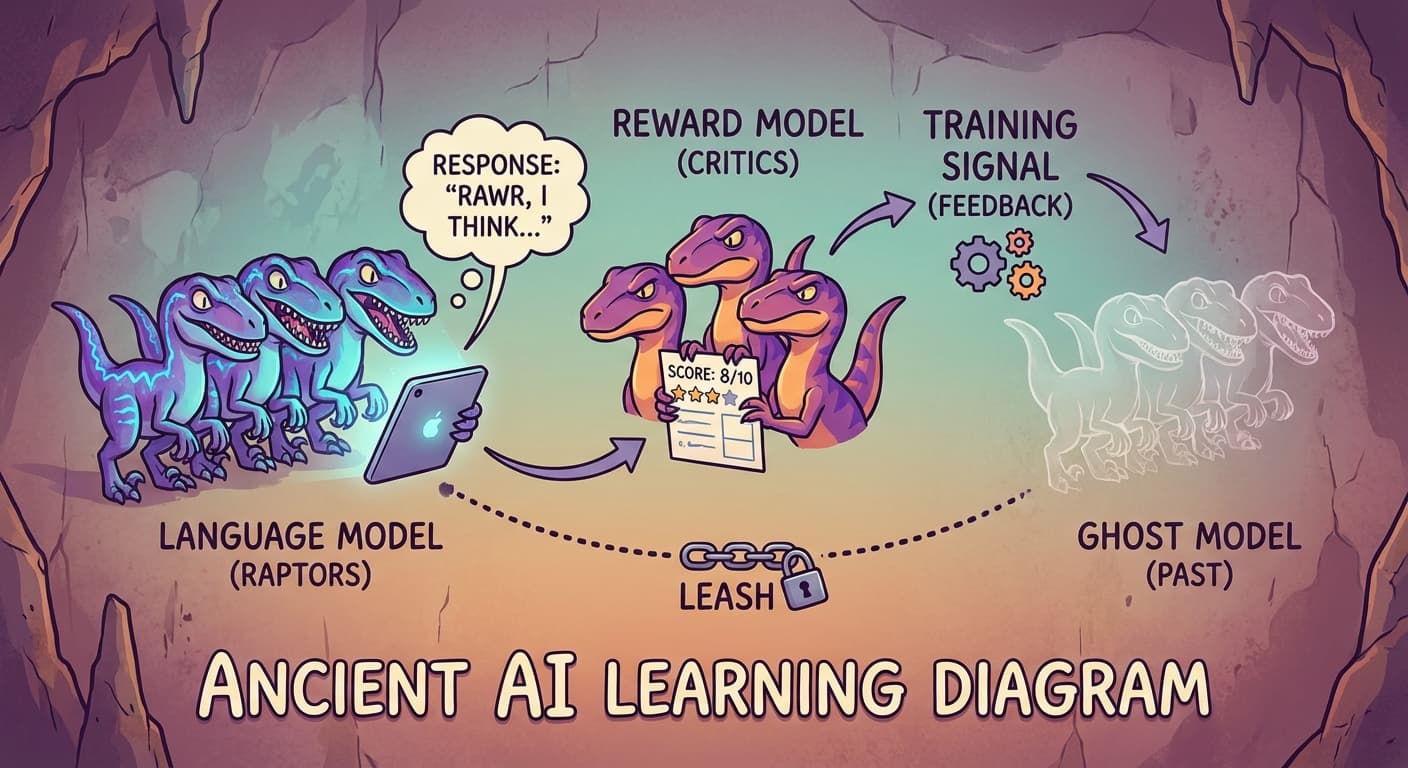
The process worked in cycles:
Step 1: Give the language model a question from Zhrondvik's reports.
Step 2: The language model generates a response — token by token, using its current weights.
Step 3: The reward model scores the response. Higher scores for responses that match the patterns of human-preferred outputs.
Step 4: Use the reward model's score as the reinforcement learning reward. Adjust the language model's weights to produce responses that score higher.
Step 5: Repeat.
Trviksha: The language model is the agent. The question is the state. The generated response is the action. The reward model's score is the reward. I am using reinforcement learning to train the language model to produce responses that the reward model rates highly.
Blortz: The pterodactyl learned to deliver packages by trial and error, using a reward signal. The language model learns to write good summaries by trial and error, using the reward model's score.
Trviksha: Same framework. Different domain.
The Constraint
There was a danger. The language model had been pre-trained on hundreds of millions of tokens. It had learned grammar, facts, reasoning patterns, and general language competence. If the reinforcement learning process was too aggressive — if it pushed the model too hard toward high-reward responses — it might distort the model, losing the general knowledge in pursuit of high scores.
Trviksha added a constraint: the fine-tuned model should not drift too far from the original pre-trained model. At each step, she measured how different the fine-tuned model's outputs were from what the original model would have produced. If the difference grew too large, the fine-tuning was penalized.
Trviksha: The pre-trained model knows how to write coherent, factual text. The fine-tuning should adjust its style and focus — making it more specific, more actionable, more directly helpful — without destroying its underlying competence. The constraint keeps the fine-tuned model close to the original.
Blortz: A leash. The model can wander toward higher reward, but not too far from where it started.
The Results
After fine-tuning for several hundred cycles, the model's summaries changed noticeably.
Before fine-tuning: "This report discusses grain production in the eastern provinces. Several factors are noted that may affect output. The situation merits continued observation."
After fine-tuning: "Eastern grain production is down 30% year-over-year. Three districts — Klomvaj, Threnjik, and Grontbek — report stocks below the six-week threshold. Recommendation: authorize emergency redistribution from the southern surplus before the monsoon disrupts transport."
Zhrondvik: That is what I need. Specific. Direct. Actionable. It even flags the transport risk I would not have thought of.
The fine-tuned model scored substantially higher on the reward model — an average of 7.2 versus the original model's 4.1, on the reward model's internal scale. More importantly, when Zhrondvik's reviewers compared the fine-tuned model's outputs with the original model's outputs on new questions, they preferred the fine-tuned version eighty-four percent of the time.
Trviksha: The pipeline works. Pre-train on general text to build language competence. Collect human preferences on what "good" looks like. Train a reward model on those preferences. Fine-tune the language model using the reward model's scores. The result is a model that retains its general knowledge but produces outputs that humans judge as more helpful.
Glagalbagal: Four stages. Each building on the last. How many pebble arrangements is that in total?
Blortz: An extraordinary number. But the result is a model that writes better government briefings than most of Zhrondvik's human staff. Whether that says more about the model or about the staff, I leave to you.