Part 28 of 58
The Lookup
By Madhav Kaushish · Ages 12+
The recurrent approach failed on long contracts because information had to travel through every intermediate position. Trviksha needed a direct connection — a way for any position to access any other position without passing through the ones in between.
The Bulletin Board
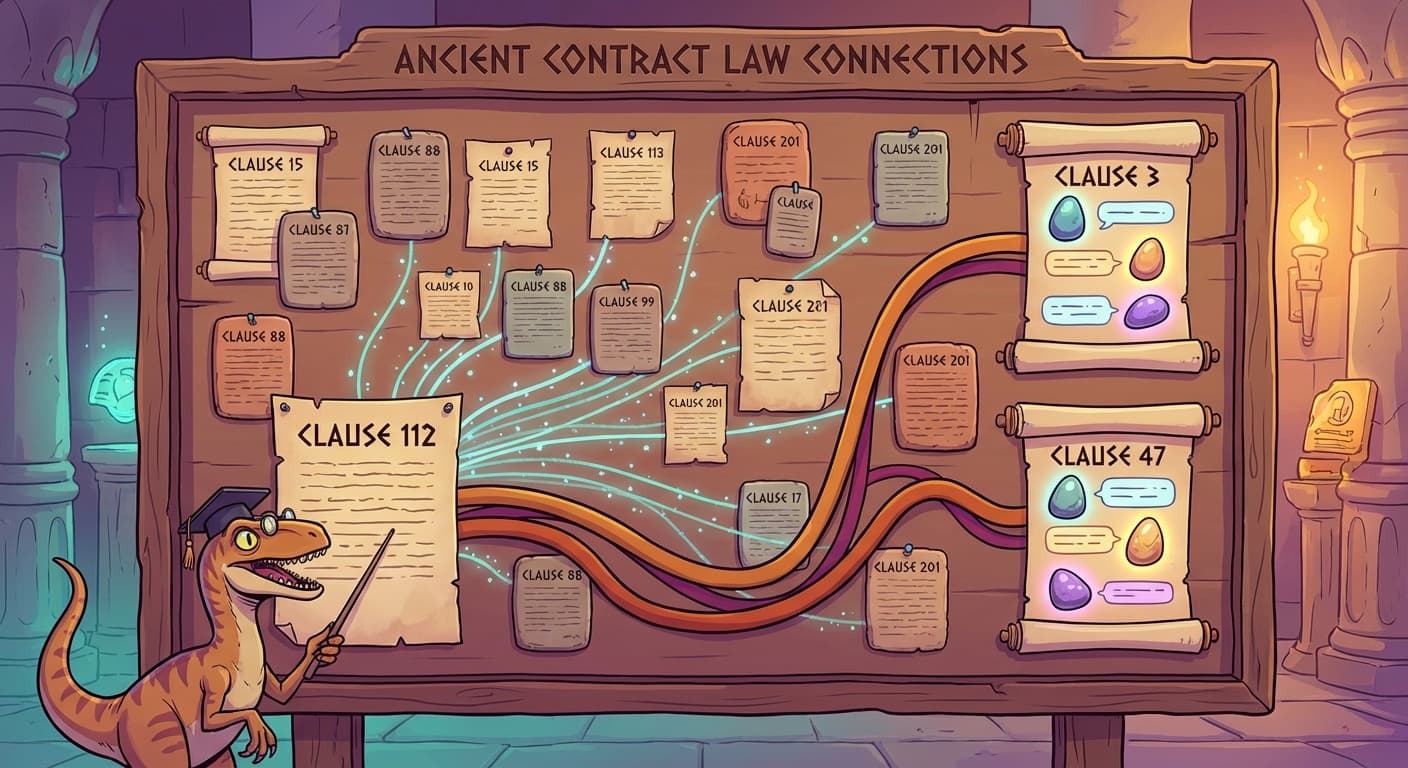
She started with a physical analogy. Imagine every clause of the contract pinned to a bulletin board simultaneously. When processing Clause 112, instead of relying on a compressed memory, the velociraptor at Clause 112 could look at the entire bulletin board — every clause, all at once — and decide which ones were relevant.
Trviksha: No more reading left to right. Every clause is available at all times. The question is: how does the velociraptor at Clause 112 know which other clauses to pay attention to?
Blortz: It cannot look at all of them equally. A hundred and fifty clauses, each with dozens of tokens — that is too much information to absorb at once.
Trviksha: Right. So each position assigns a relevance score to every other position. High scores for relevant clauses, low scores for irrelevant ones. Then the position takes a weighted combination — emphasizing the relevant clauses and ignoring the irrelevant ones.
The Mechanism
She implemented it as follows. For a contract with two thousand tokens, each token was represented by its encoding — the pebble arrangement that captured its meaning. When processing any particular token — say, token 1,500 — the system computed a relevance score between token 1,500 and every other token in the sequence.
The relevance score was simple: how similar was the current token's "question" to each other token's "content"? If token 1,500 was asking about delivery deadlines, and token 50 contained deadline information, the score between them would be high. If token 800 was about payment terms — irrelevant to the current question — the score would be low.
The scores were then converted into weights that summed to one (using the same softmax function that classified grain stores in earlier parts). Each weight represented how much of the corresponding token's information to include.
Trviksha: Token 1,500 looks at all two thousand tokens. It assigns each one a relevance weight. Then it computes a weighted average of their information — taking a lot from the relevant tokens and almost nothing from the irrelevant ones. The result is a "summary" of the rest of the sequence, tailored specifically to what token 1,500 needs.
Drysska: Every token does this?
Trviksha: Every token. Token 1 looks at all two thousand tokens and computes its own tailored summary. Token 2 does the same. Token 2,000 does the same. Each token gets its own personalised view of the entire sequence.
The Direct Connection
The critical difference from the recurrent approach: the connection between token 50 and token 1,500 was direct. No intermediate tokens. No sequential processing. No information passing through tokens 51, 52, 53... all the way to 1,499. The relevance score between tokens 50 and 1,500 was computed in a single step — a comparison between two token representations, nothing more.
Blortz: In the recurrent network, information from token 50 had to survive through 1,450 sequential steps. In this system, token 1,500 simply looks at token 50 directly. The information arrives intact, uncompressed, unmodified by anything in between.
Phlontjek: Like flipping to Clause 3 when you need it, instead of rereading the whole contract.
Trviksha: Exactly. Except the network does not know in advance that it needs Clause 3. It computes relevance scores for every clause and lets the scores determine where to look. The "flipping" happens automatically, learned from the data.
She tested the system on Phlontjek's contracts. Each token attended to every other token — computed relevance scores and took weighted combinations. The output was processed through a standard hidden layer and produced answers to questions about the contract.
Accuracy on contract questions: 84% for short contracts (same as the recurrent approach) and 79% for long contracts (compared to 52% for the recurrent approach). The improvement on long contracts was dramatic.
Phlontjek: Now it gets Clause 3's deadline right even from Clause 112. The early information is not lost.
Trviksha: Because the early information was never compressed. It was available directly, on the bulletin board, the entire time.
The Cost
Blortz: I have a concern about scale.
Every token looked at every other token. For a two-thousand-token contract, each token computed two thousand relevance scores. Across all two thousand tokens, that was two thousand times two thousand — four million relevance computations for a single contract.
Blortz: Four million comparisons. For a four-thousand-token document, it would be sixteen million. The cost grows with the square of the length.
Trviksha: I know. But for contracts of a few thousand tokens, it is feasible. And the improvement over sequential processing is worth the cost.
She filed the quadratic cost as a problem for later — when, and if, she needed to process much longer documents.