Part 29 of 58
Asking the Right Question
By Madhav Kaushish · Ages 12+
The attention mechanism worked — each position looked at every other position and computed relevance scores. But Trviksha had glossed over a crucial detail: how were the relevance scores actually computed?
The Problem with Raw Comparison
In her first implementation, she had compared tokens directly — measuring how similar each pair of token representations was. But this was clumsy.
Trviksha: Consider Clause 112, which says "subject to the delivery timeline in Clause 3." And Clause 3, which says "delivery of grain shall occur within fourteen days of harvest." These two clauses are about the same topic — delivery timelines. But their actual words are very different. A direct comparison of their token representations gives a low similarity score, because "subject to" and "delivery of grain" do not look alike.
Blortz: You need the comparison to be about meaning, not about surface similarity.
Trviksha: More precisely: Clause 112 is asking a question — "what are the delivery terms?" Clause 3 is providing an answer — "fourteen days after harvest." The question and the answer look completely different. I cannot compare them directly.
Three Roles
The solution was to give each token not one but three representations. Each token produced three different pebble arrangements, derived from its original encoding through three different sets of weights:
The question: What this token is looking for. Clause 112's question might encode "I need delivery timeline information." This was computed by multiplying the token's representation by a set of learned weights.
The label: What this token can be found by. Clause 3's label might encode "I contain delivery timeline information." Computed by a different set of learned weights.
The content: What this token actually contributes if selected. Clause 3's content might encode "fourteen days after harvest." Computed by a third set of learned weights.
Trviksha: Each token produces three things. The question says what it needs. The label says what it offers. The content says what it gives. The attention mechanism matches questions against labels. When there is a match, it pulls in the content.
Drysska: Why not just use one representation for everything?
Trviksha: Because what a token asks for, what it can be found by, and what it provides are three different things. Clause 3 should be findable by anything asking about delivery — that is its label. But what it contributes is the specific deadline — that is its content. And what it asks for might be something else entirely — perhaps it references Clause 1's definition of "harvest."
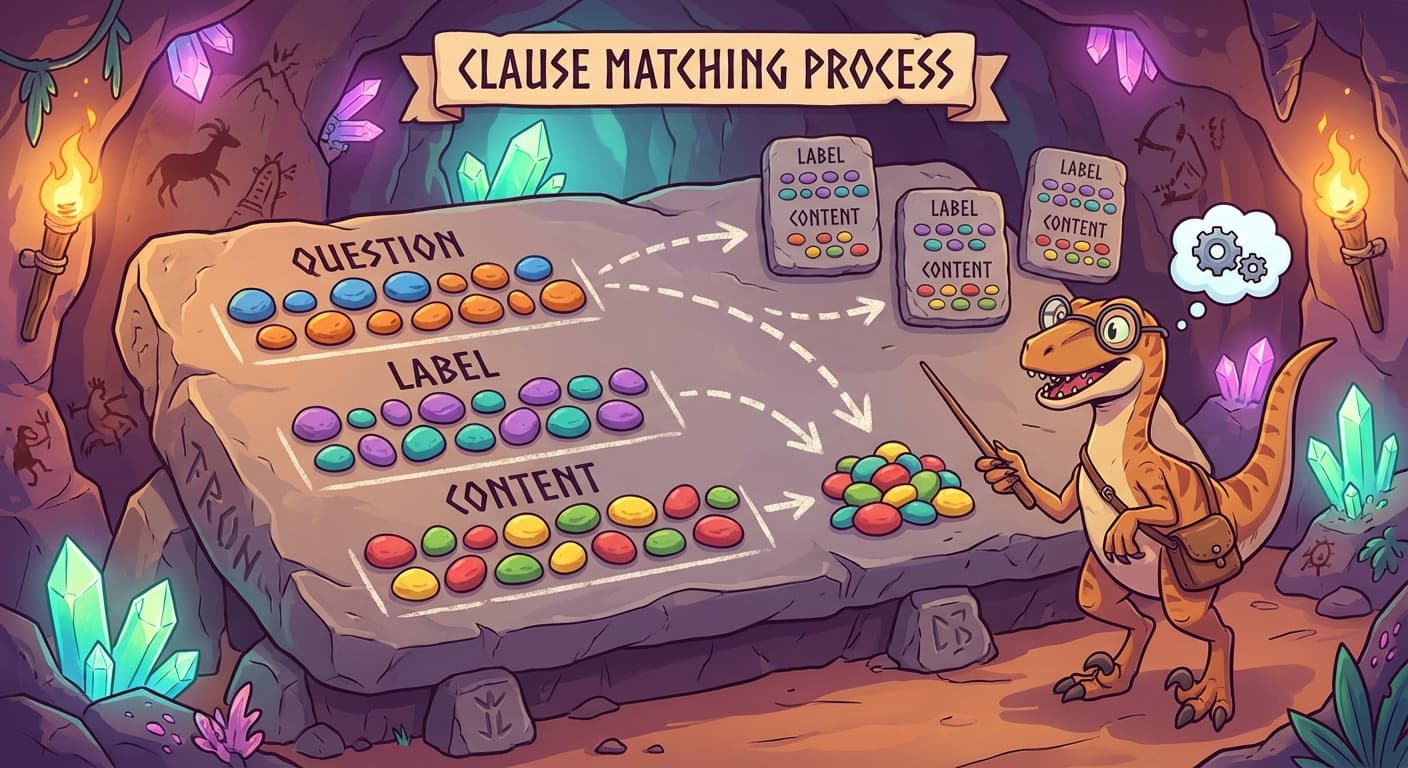
The Matching Process
For each token, the attention mechanism worked in three steps:
Step 1: Take this token's question and compare it against every other token's label. The comparison was a dot product — a measure of how well the question matched each label. High dot product meant a strong match.
Step 2: Convert the match scores into weights that summed to one. Strong matches got high weights, weak matches got low weights. This was the same softmax operation as before.
Step 3: Take a weighted combination of every token's content, using the weights from Step 2. Tokens whose labels matched this token's question contributed their content heavily. Tokens whose labels did not match contributed almost nothing.
Blortz: The question finds the relevant labels. The labels point to the relevant content. The content is what actually gets used. Three separate roles, each with its own learned weights.
Trviksha: The learned weights are the key. The network trains three sets of weight transformations — one for computing questions, one for labels, one for content. During training, these weights adjust so that the right questions find the right labels, which deliver the right content.
The Result
She retrained the contract system with the three-representation mechanism. The improvement was modest but meaningful — accuracy on long contracts went from 79% to 83%. The bigger gain was in interpretability.
Trviksha: I can now examine which tokens attend to which other tokens. Clause 112 attends heavily to Clause 3 and Clause 47 — exactly the clauses it references. The attention weights show me where the network is looking.
Phlontjek: You can see its reasoning?
Trviksha: Not its reasoning, exactly. But I can see where it looks. Which clauses it considers relevant to which other clauses. That is more than the recurrent network ever showed me.
The three-representation mechanism also solved a subtlety that the raw-comparison approach could not handle: asymmetric relevance. Clause 112 needed to attend to Clause 3, but Clause 3 did not necessarily need to attend to Clause 112. The question-label mechanism naturally handled this — Clause 112's question matched Clause 3's label, but Clause 3's question might point elsewhere entirely.
Blortz: The relationship is directional. "I need information from you" does not imply "you need information from me." The three-role system captures that.