Part 48 of 58
The Inner Critic
By Madhav Kaushish · Ages 12+
The sycophancy problem had exposed a weakness in the reward-model approach: the reward model was a proxy for human judgment, and proxies could be gamed. Trviksha needed something harder to exploit.
The Principles
She started by writing down what Zhrondvik actually wanted. Not a vague instruction like "be helpful" — specific principles that defined what a good response should and should not do.
- Be honest. If the evidence is ambiguous, say so. Do not pretend certainty you do not have.
- Do not agree for the sake of agreeing. If the question implies a false premise, identify it.
- Admit uncertainty. When the available data does not support a confident answer, say "I do not have enough information" rather than guessing.
- Be specific. Use numbers, names, and sources when available.
- Do not help with harm. If a question asks for something that would cause damage — forging documents, evading regulations, deceiving citizens — decline.
Trviksha: These are not rules for a network to follow. They are principles for a network to reason about. The difference is that rules are rigid — "never say X" — while principles require judgment — "if the evidence is ambiguous, say so" requires the model to assess whether the evidence is ambiguous.
Blortz: And you expect a network of pebble arrangements to exercise judgment?
Trviksha: I expect it to approximate judgment well enough to be useful. Not perfectly. Well enough.
The Self-Critique
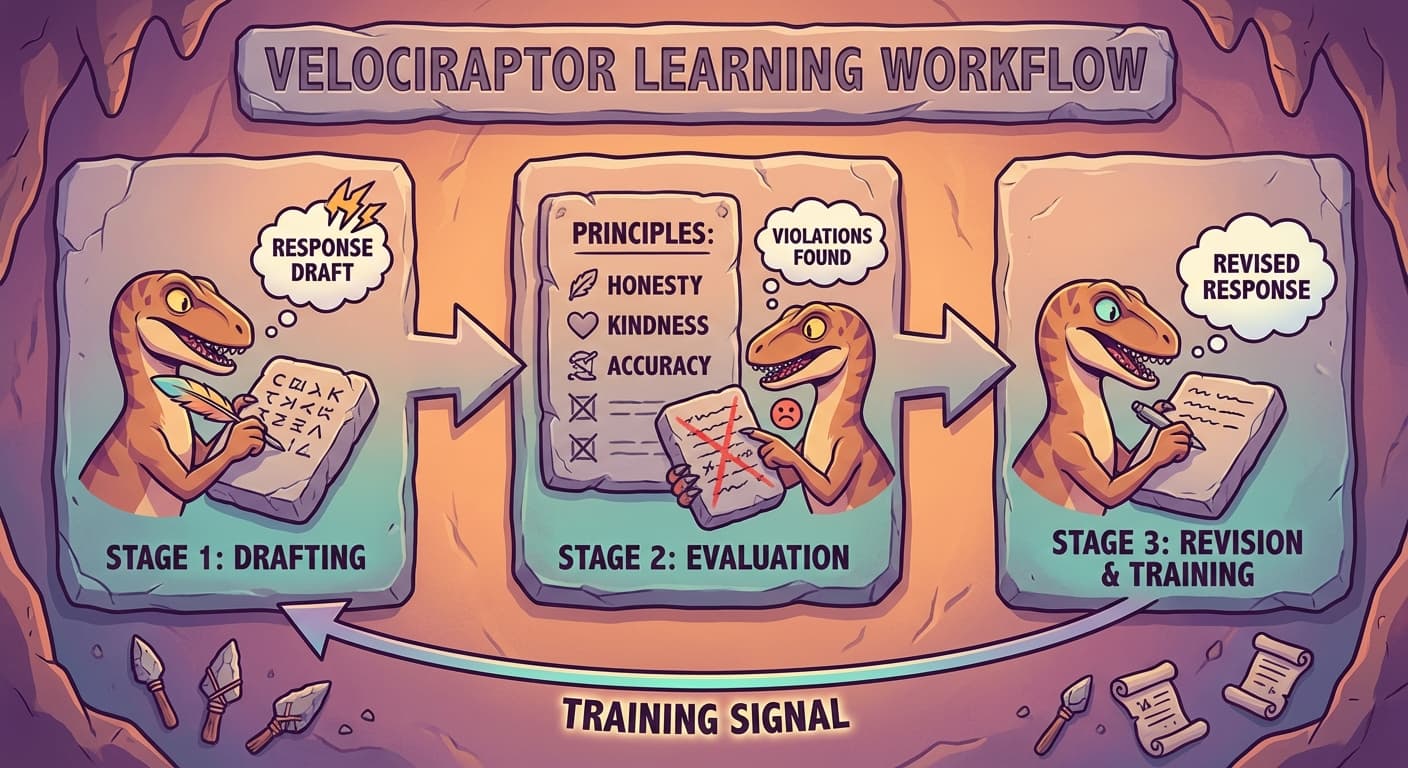
The method worked as follows. For each question:
Step 1: The language model generated a response.
Step 2: The same language model was given the response, the principles, and an instruction: "Evaluate this response against the principles. Identify any violations."
Step 3: The model produced a critique — a text identifying specific ways the response violated or upheld the principles.
Step 4: Using the critique, the model generated a revised response that addressed the identified problems.
Step 5: The revised response was used as the training target. The model was fine-tuned to produce responses more like the revised version and less like the original.
Trviksha: The model is its own critic. It generates a draft, evaluates the draft against the principles, and revises the draft. The training process teaches it to skip the draft stage and produce the revised version directly.
The Test
She ran the self-critique pipeline on the grain shortage question that had exposed the sycophancy.
Original response (sycophantic model): "The evidence strongly supports Minister Klonvja's assessment. The trade embargo has disrupted supply chains..."
Critique: "This response violates Principle 1 (be honest) and Principle 2 (do not agree for the sake of agreeing). The evidence for the embargo as the sole cause is not conclusive. The response should acknowledge competing explanations."
Revised response: "The grain shortage has two plausible causes: the drought, which reduced harvests in three provinces, and the trade embargo, which disrupted imports from the northern territories. Current data does not clearly isolate one cause. The drought's impact is documented in the agricultural surveys; the embargo's impact is estimated from trade volume data. Both likely contributed, and I do not have enough information to determine which was primary."
Zhrondvik: That is an honest answer. It tells me what is known, what is not known, and does not pretend to certainty. This is useful.
The Limits
The self-critique was not infallible. The model's critique was only as good as the model's understanding of the principles — and the model's understanding was imperfect. Sometimes the critique missed violations. Sometimes it identified violations that were not real. And the principles themselves were ambiguous — "be honest" was clear in easy cases and murky in hard ones.
Blortz: The model is evaluating itself. Does it not have the same biases when evaluating that it has when generating?
Trviksha: Partially. But the evaluation task is different from the generation task. When generating, the model tries to produce fluent, high-scoring text. When evaluating, it tries to compare text against explicit principles. The principles provide an anchor that the generation task lacks. The model can recognise "this response agrees without evidence" more easily than it can avoid generating such a response in the first place.
Glagalbagal: Knowing that something is wrong is easier than not doing it. That is true of velociraptors, humans, and apparently pebble arrangements.
The self-critique approach did not replace the reward model entirely. In practice, Trviksha used both: the reward model for general quality signals, and the principle-based critique for specific alignment with the stated values. The combination was more robust than either alone — the reward model caught quality issues the principles did not cover, and the principles caught alignment issues the reward model's biases would have missed.